Method

How does it work?
-
Step 1
DistilRoBERTa was pre-trained on millions of texts: it integrates a very diverse vocabulary, and understands the peculiarities of the English language, its conjugation and grammar rules. At this stage, the model was not yet specialized in the recognition of the SDGs.
-
Step 2
To be able to detect the SDGs in a text, the SDG Prospector needed further training.
We constructed an expert learning base composed of 9000+ paragraphs related
to the SDGs. -
Step 3
Thanks to its deep neural network, its excellent command of English and the expert learning base, the SDG Prospector automatically learnt to detect whenever a text refers to the 2030 Agenda, and to distinguish the SDGs from one another.
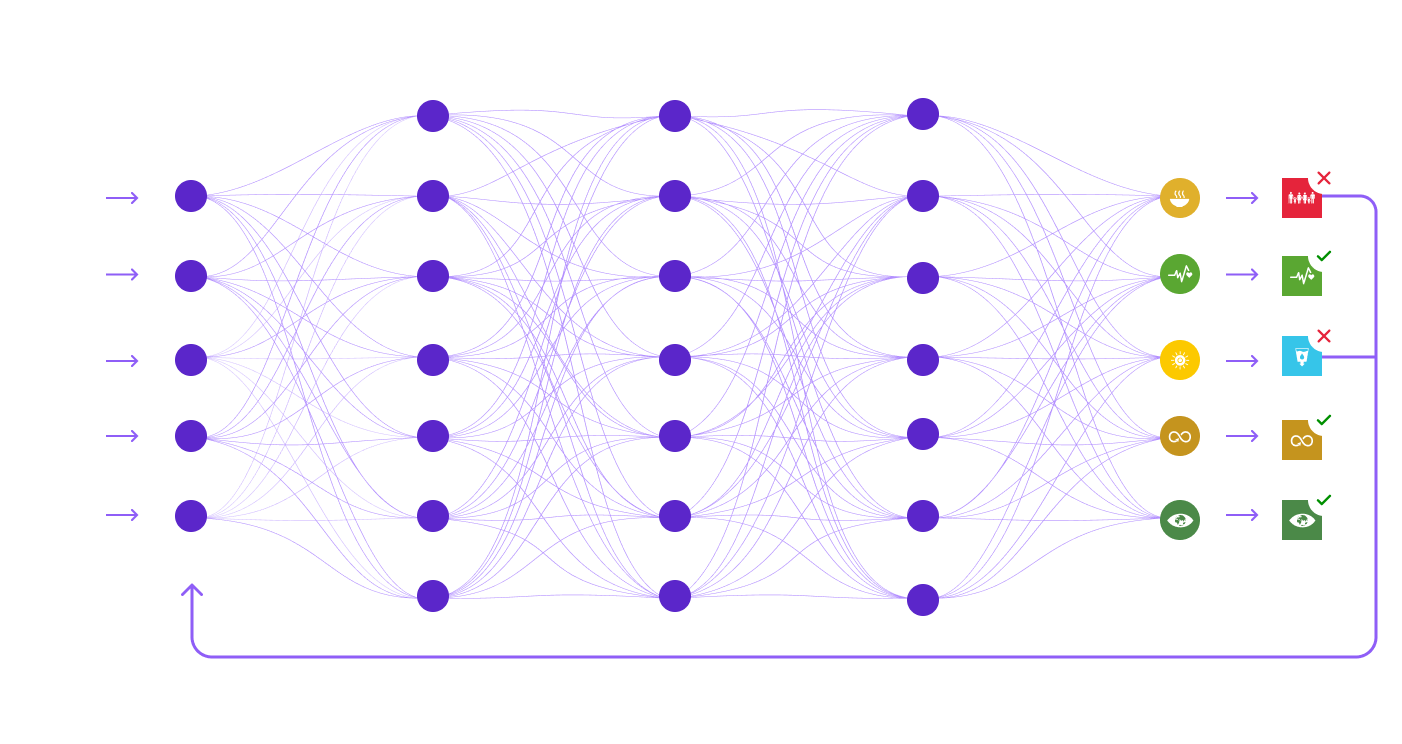
-
Step 4
After a series of robustness tests and fine-tuning, the SDG Prospector was born.

Importance of the learning base
The accuracy of the SDG Prospector derives directly from the quality of the learning base. Exclusively built by selecting relevant texts manually, our learning base consists of over 9,000 paragraphs related to the SDGs. For each SDG, we collected more
than 500 paragraphs, of maximum 200 words. These were mostly extracted
from specialized UN official documents and completed with texts from other sources.


Besides an exclusion universe teaches the algorithm not to confuse concepts that use the same vocabulary as the SDGs but do not refer to the 2030 Agenda. To illustrate, supporting the business climate has nothing to do with the fight against climate change and its impacts.
How does the SDG Prospector analyse documents?
-
The SDG Prospector parses the text in 100-word paragraphs.
-
It assesses whether each paragraph is related to one, several or no SDG.
-
It automatically sums up SDG references.
-
You can view your results in absolute or in relative values, to take into account the length of your document.